

-


编程语言
站-
热门城市 全国站>
-
其他省市
-
-

 400-636-0069
400-636-0069
 安安
2017-12-25
来源 :网络
阅读 1007
评论 0
安安
2017-12-25
来源 :网络
阅读 1007
评论 0
摘要:本篇C#程序设计教程将为大家讲解C#程序设计的知识点,看完这篇文章会让你对C#编程的知识点有更加清晰的理解和运用。
本篇C#程序设计教程将为大家讲解C#程序设计的知识点,看完这篇文章会让你对C#编程的知识点有更加清晰的理解和运用。
动态创建函数
大多数同学,都或多或少的使用过。回顾下c#中动态创建函数的进化:
C# 1.0中:
public delegate string DynamicFunction(string name);
public static DynamicFunction GetDynamicFunction()
{
return GetName;
}
static string GetName(string name)
{
return name;
}
var result = GetDynamicFunction()("mushroom");
3.0写惯了是不是看起来很繁琐、落后。 刚学委托时,都把委托理解成函数指针,也来看下用函数指针实现的:
char GetName(char p);typedef char (*DynamicFunction)(char p);DynamicFunction GetDynamicFunction(){
return GetName;
}char GetName(char p){
return p;
};char result = GetDynamicFunction()('m');
对比起来和c# 1.0几乎一模一样了(引用/指针差别),毕竟是同一家族的。
C# 2.0中,增加匿名函数:
public delegate string DynamicFunction(string name);
DynamicFunction result2 = delegate(string name)
{
return name;
};
C# 3.0中,增加Lambda表达式,华丽的转身:
public static Func<string, string> GetDynamicFunction()
{
return name => name;
}
var result = GetDynamicFunction()("mushroom");
匿名函数不足之处
虽然增加Lambda表达式,已经极大简化了我们的工作量。但确实有些不足之处:
var result = name => name;
这些写编译时是报错的。因为c#本身强类型语言的,提供var语法糖只是为了省去声明确定类型的工作量。 编译器在编译时必须能够完全推断出各参数的类型才行。代码中的name参数类型,显然在编译时无法推断出来的。
var result = (string name) => name;
Func<string, string> result2 = (string name) => name;
Expression<Func<string, string>> result3 = (string name) => name;
上面直接声明name类型呢,很遗憾这样也是报错的。代码中已经给出答案了,编译器推断不出右边表达式是属于Func<string, string>类型还是Expression<Func<string, string>>类型。
dynamic result = name => name;
dynamic result1 = (Func<string,string>)(name => name);
用dynamic呢,同样编译器也分不出右边是个委托,我们显示转换下就可以了。
Func<string, string> function = name => name;
DynamicFunction df = function;
这里定义个func委托,虽然参数和返回值类型都和DynamicFunction委托一样,但编译时还是会报错:不能隐式转换Func<string, string>到DynamicFunction,2个类型是不兼容的。
理解c#中的闭包
谈论到动态创建函数,都要牵扯到闭包。闭包这个概念资料很多了,理论部分这里就不重复了。 来看看c#代码中闭包:
Func<Func<int>> A = () =>
{
var age = 18;
return () => //B函数
{
return age;
};
};
var result = A()();
上面就是闭包,可理解为就是: 跨作用域访问函数内变量,也有说带着数据的行为。
C#变量作用域一共有三种,即:类变量,实例变量,函数内变量。子作用域访问父作用域的变量(即函数内访问实例/类变量)在我们看来理所当然的,也符合我们一直的编程习惯。
例子中匿名函数B是可以访问上层函数A的变量age。对于编译器而言,A函数是B函数的父作用域,所以B函数访问父作用域的age变量是符合规范的。
int age = 16;
void Display()
{
Console.WriteLine(age);
int age = 18;
Console.WriteLine(age);
}
上面编译会报错未声明使用,编译器检查到函数内声明age后,作用域就会覆盖父作用域的age,(像JS就undefined了)。
Func<int> C = () =>
{
var age = 19;
return age;
};
上面声明个同级函数C,那么A函数是无法访C函数中的age变量的。 简单来说就是不可跨作用域访问其他函数内的变量。 那编译器是怎么实现闭包机制的呢?
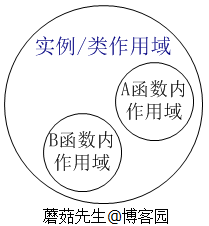
如上图,答案是升级作用域,把A函数升级为一个实例类作用域。 在编译代码期间,编译器检查到B函数使用A函数内变量时,会自动生成一个匿名类x,把原A函数内变量age提升为x类的字段(即实例变量),A函数提升为匿名类x的实例函数。下面是编译器生成的代码(精简过):
class Program1
{
static Func<Func<int>> CachedAnonymousMethodDelegate2;
static void Main(string[] args)
{
Func<Func<int>> func = new Func<Func<int>>(Program1.B);
int num = func()();
}
static Func<int> B()
{
DisplayClass cl = new DisplayClass();
cl.age = 18;
return new Func<int>(cl.A);
}
}sealed class DisplayClass
{
public int age;
public int A()
{
return this.age;
}
}
我们再来看个复杂点的例子:
static Func<int, int> GetClosureFunction()
{
int val = 10;
Func<int, int> interAdd = x => x + val;
Console.WriteLine(interAdd(10));
val = 30;
Console.WriteLine(interAdd(10));
return interAdd;
}
Console.WriteLine(GetClosureFunction()(30));
输出结果是20、40、60。 当看到这个函数内变量val通过闭包被传递的时候,我们就知道val不仅仅是个函数内变量了。之前我们分析过编译器怎么生成的代码,知道val此时是一个匿名类的实例变量,interAdd是匿名类的实例函数。所以无论val传递多少层,它的值始终保持着,直到离开这个(链式)作用域。
关于闭包,在js当中谈论的比较多,同理,可以对比理解下:
function A() {
var age = 18;
return function () {
return age;
}
}
A()();
包的优点闭
· 对变量的保护。想暴露一个变量值,但又怕声明类或实例变量会被其他函数污染,这时就可以设计个闭包,只能通过函数调用来使用它。
· 逻辑连续性和变量保持。 A()是执行一部分逻辑,A()()仅接着A()逻辑继续走下去,在这个逻辑上下文期间,变量始终都被保持着,可以随意使用。
本文由职坐标整理并发布,希望对同学们学习C#编程的知识有所帮助。了解更多详情请关注职坐标C#频道!
 喜欢 | 0
喜欢 | 0
 不喜欢 | 0
不喜欢 | 0


您输入的评论内容中包含违禁敏感词
我知道了

请输入正确的手机号码
请输入正确的验证码
您今天的短信下发次数太多了,明天再试试吧!
我们会在第一时间安排职业规划师联系您!
您也可以联系我们的职业规划师咨询:

版权所有 职坐标-一站式IT培训就业服务领导者 沪ICP备13042190号-4
上海海同信息科技有限公司 Copyright ©2015 www.zhizuobiao.com,All Rights Reserved.
 沪公网安备 31011502005948号
沪公网安备 31011502005948号






 索取资料
索取资料

 答疑解惑
答疑解惑

 技术交流
技术交流

 职业测评
职业测评

 面试技巧
面试技巧

 高薪秘笈
高薪秘笈




